在QCon全球软件开发大会上,月之暗面系统工程师黄维啸分享了关于构建稳定高效的大型语言模型(LLM)基础设施的经验。黄维啸详细介绍了月之暗面在混合训练和推理集群中的实践,着重探讨了如何迅速定位并解决故障,实现任务快速恢复,从而提升系统稳定性。
黄维啸首先指出,在大规模训推集群中,他们面临了诸多挑战。随着资源规模的扩大,故障频率显著增加,导致任务频繁中断,严重影响训练效率。为此,他们开发了一系列措施来快速监测和恢复故障。其次,资源使用效率低下也是一个突出问题,尤其是在云服务环境中,开发机和文件存储存在大量浪费。大模型应用和线上服务存在潮汐效应,需要根据时间动态分配资源。最后,在强化学习中,如何平衡训练和推理的效率,使资源得到高效利用,也是他们需要解决的重要问题。
为了提升全链路稳定性,月之暗面实施了全面的监控体系,包括任务全生命周期的监控、调用栈全链路监控、智能日志分析以及连续异步checkpoint机制。他们通过Precheck和周期巡检来预防故障,利用调用栈监控来定位问题,并通过智能日志分析生成详细的任务分析报告。他们还开发了连续异步checkpoint机制,确保任务在失败后能迅速从最新checkpoint加载,提高了任务恢复的效率。

在提高资源利用率方面,月之暗面采取了多种策略。他们实现了动态申请云上开发资源,允许用户根据需要动态启动GPU worker,提高了资源使用的灵活性。他们还开发了任意级目录用量统计功能,帮助用户管理文件系统中的资源。在模型评估方面,他们实现了模型的异步evaluation,利用空闲资源进行模型评估,提高了GPU资源的利用效率。
月之暗面还实现了跨机房推理模型分发功能和训推多级潮汐系统,进一步提高了资源利用效率。跨机房推理模型分发功能通过P2P模式拉取和缓存模型,显著缩短了模型拉取时间。训推多级潮汐系统则根据任务优先级和流量情况动态调整资源分配,确保在线推理服务的稳定运行,同时最大化利用GPU资源。
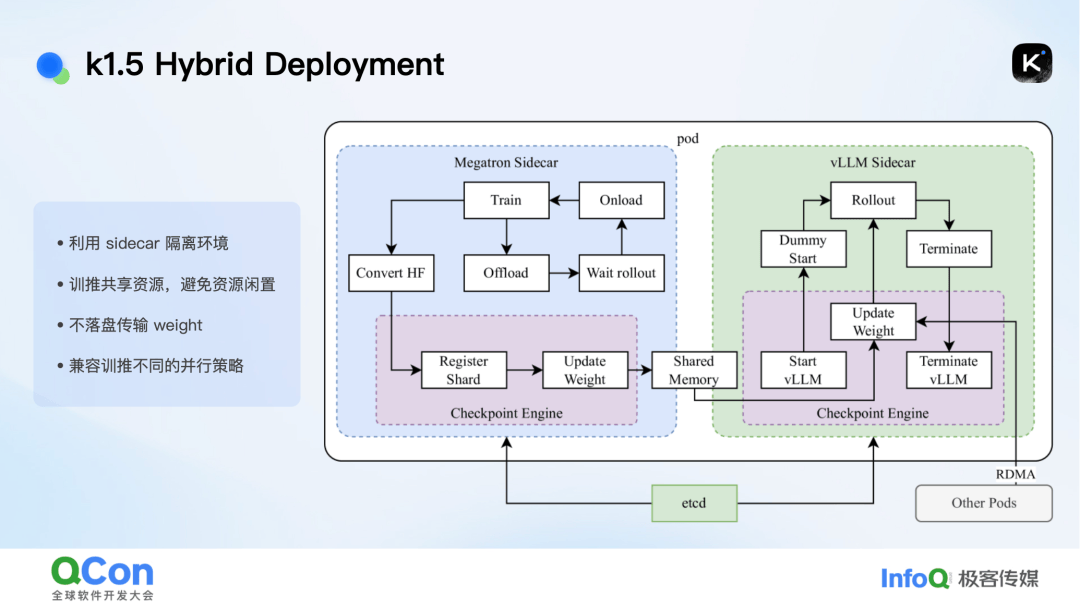
在强化学习方面,月之暗面也面临了诸多挑战。他们设计了一套完善的IO系统,采用Hybrid deployment方式将训练和推理任务分离到不同的sidecar容器中,实现了资源的共享和高效利用。他们还开发了partial rollout和greedy rollout机制,解决了长链式推理场景下的长尾问题,提高了GPU资源的利用率。
黄维啸还介绍了月之暗面在强化学习中的混合部署策略。他们利用RDMA和内存传输技术实现了训练和推理权重的高效传输,避免了资源的闲置和浪费。同时,他们通过启动isolated Pod来应对推理任务对更多资源的需求,提高了系统的吞吐能力。
黄维啸在演讲中分享的这些实践经验和技术思考,为关注大规模模型训练的同行们提供了宝贵的参考。他强调,通过不断优化和创新,可以实现更高效、更稳定的LLM基础设施构建。
黄维啸是月之暗面的系统工程师,拥有7年AI Infra系统经验。他曾在旷视科技公司主导公司AI平台Brain++的研发工作,对AI基础设施构建有着深入的理解和丰富的实践经验。