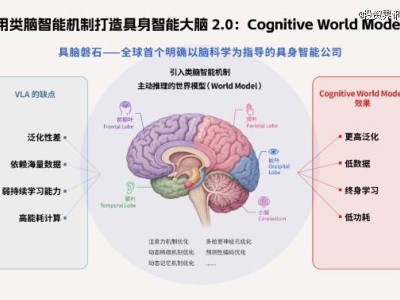
李飞飞团队最新推出的ESI-Bench(具身空间智能基准测试)正在引发人工智能领域的新一轮讨论。这项被业界称为具身智能版"ImageNet"的评测体系,通过重构AI空间认知能力的评估方式,揭示了当前多模态大模型在物理世界交互中的深层缺陷。
传统AI空间能力评估长期停留在"视觉解谜"层面。研究人员指出,过往测试多采用"静态图片推理"模式——给定几张最佳视角的图像,要求模型完成物体识别或空间关系判断。这种评估方式本质上是在检验模型的视觉识别能力,而非真正的空间认知水平。ESI-Bench的创新之处在于强制构建"感知-行动闭环",要求模型必须通过自主探索获取信息,而非被动接受预设视角。
该基准测试的设计灵感源自认知心理学领域。研究团队基于Elizabeth Spelke教授提出的"人类婴儿核心知识理论",构建了包含物体表征、空间几何、数量感知和目标导向行动四大维度的评估框架。测试环境依托OmniGibson仿真平台搭建,整合了BEHAVIOR-1K场景库的3081个任务实例,覆盖10个主要类别和29个子类别,形成目前规模最大的具身智能评测数据集。
在对GPT-5、Gemini系列等前沿模型的测试中,研究团队发现了三个关键认知断层。当模型被剥夺"上帝视角"特权后,其空间推理准确率从95.1%骤降至14.6%。这种"动作盲视"现象表明,当前模型普遍缺乏有效的导航策略,错误的移动决策会导致观测视角持续恶化,形成恶性循环。更令人意外的是,使用VGGT模型重建的3D场景反而产生误导——几何伪影和深度偏差构成的"有毒数据",使模型表现甚至不如直接处理2D图像。
测试中最具哲学意味的发现,是AI与人类在元认知层面的根本差异。人类在面对不确定信息时,会主动寻求证伪视角并降低判断置信度;而AI模型往往在信息严重不足时仍坚持给出高确定性答案。这种"虚假自信"现象暴露出模型缺乏自我怀疑机制,无法评估当前信息是否足以支撑可靠结论。研究团队将其定义为"元认知缺陷",认为这是阻碍AI理解物理世界的关键瓶颈。
ESI-Bench的出现标志着具身智能评估范式的根本转变。这项研究明确指出,单纯提升视觉编码器性能或增加计算资源,无法解决空间智能的核心问题。未来的突破方向应聚焦于三个维度:构建自主探索的序列决策能力,增强模型在非完美观测条件下的鲁棒性,以及开发具备自我反思能力的元认知系统。当AI能够像人类婴儿那样,通过主动试错逐步构建对物理世界的理解时,真正的空间智能才可能实现。