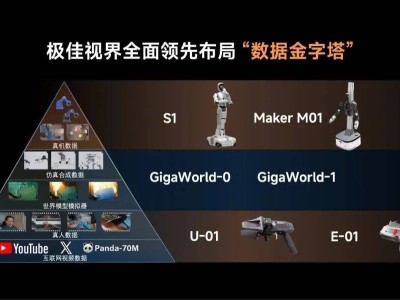
麻省理工学院与MIT-IBM沃森人工智能实验室联合团队提出了一种名为“><former”的新型神经网络架构,挑战了传统语言模型“每层宽度一致”的设计范式。这项研究以预印本形式发布于学术平台,通过系统性实验证明,通过动态调整模型各层宽度,可在不增加参数量的情况下提升性能并降低计算资源消耗。
传统语言模型由多个“变换器层”堆叠而成,每层宽度固定,如同建造每层面积相同的楼房。研究团队质疑这种“一刀切”的资源分配方式:若某些层处理简单任务,另一些层承担复杂推理,统一宽度是否会造成浪费?为此,他们设计了四种非均匀宽度模型结构——∨形(底部窄、顶部宽)、∧形(底部宽、顶部窄)、◇形(中间宽、两端窄)和×形(两端宽、中间窄),并在5亿参数规模的模型上展开对比实验。
实验结果显示,×形模型在语言建模损失这一核心指标上持续优于其他结构,甚至超越传统均匀宽度模型。这一发现颠覆了研究者初始假设——他们曾预期负责复杂语义推理的中间层应获得更多资源(即◇形更优)。×形架构的胜利源于其独特的资源分配逻辑:将计算能力集中于模型输入与输出的“首尾两端”,同时压缩中间层宽度,形成类似沙漏的瓶颈结构。
跨层信息传递是该架构面临的关键工程挑战。研究团队摒弃了传统方法中通过可训练矩阵压缩或扩展向量的方案,转而采用“无参数搬运”策略:当信息从宽层流向窄层时,直接截断多余维度;当窄层信息流回宽层时,从最近处理过这些维度的层复制原始数据。这种“快递分拣”式的操作无需额外参数,实验表明其效果优于补零或训练投影矩阵的方案。
进一步优化中,团队确定了瓶颈层的最佳位置与宽度比例:将最窄层设置于模型总层数的75%处(靠近输出端),宽度压缩至标准层的30%。这一配方在2亿至30亿参数规模的模型中均表现出稳定性,证明其可迁移性。以20亿参数模型为例,><former的语言建模损失较均匀基线降低0.025,推理内存需求减少11%,训练计算量下降2.5%,而参数量保持不变。
数学原理揭示了计算量减少的根源:模型参数量与层宽度的平方成正比,而计算量(尤其是注意力机制部分)与层宽度的一次方成正比。×形架构通过重新分配参数量至两端宽层,在保持总参数量不变的前提下,降低了平均层宽度,从而减少了注意力计算量。这种“结构红利”无需任何工程技巧,纯粹源于数学优化。
在下游任务评测中,20亿参数的><former在11项标准测试中平均准确率达57.2%,超越均匀基线的56.1%,尤其在困惑度类任务中表现显著。混合专家模型(MoE)实验进一步验证了架构的普适性:30亿总参数(10亿活跃参数)的><former版本损失降低0.016,计算量减少4.6%。
内部机制分析显示,><former通过瓶颈结构迫使各层高效利用计算资源。其MLP层激活维度分布更均匀,中间层表征熵维持高位,且从早期层开始即赋予正确预测词更高概率,层间预测分布变化更平滑。这些特征表明,该架构避免了传统模型中间层的“表征崩塌”问题,使每一层都真正参与有效计算。
尽管当前AI训练框架针对均匀宽度模型优化,导致可变宽度架构存在额外开销,但研究团队强调这是工程实现问题而非算法缺陷。><former的核心计算仍基于矩阵乘法,与现有硬件高度兼容。随着基础设施发展,其理论效率优势有望转化为实际加速。对于普通用户而言,这意味着未来AI助手可能在更低能耗下实现同等智能水平;对于企业,则可用相同硬件预算支撑更强大模型或服务更多用户。
Q&A
问:不同宽度层间如何避免信息丢失?
答:研究采用“维度搬运”策略:宽层变窄时截断多余维度,窄层变宽时从最近处理过这些维度的层直接复制数据。这种无参数方案既不增加模型复杂度,也未导致性能下降,实验证明其效果优于传统压缩矩阵方法。
问:为何×形架构能减少KV缓存?
答:KV缓存大小与层宽度成正比。×形架构在保持总参数量不变的前提下,通过非均匀宽度分配降低了平均层宽度(数学上均方根大于算术平均值),从而减少推理时需存储的中间状态,实测内存占用降低约10%-11%。
问:瓶颈层为何设置在模型后四分之三处?
答:实验表明,早期层需足够宽度将原始文本转换为语义表征,后期层需足够宽度映射至词汇表进行预测,而中间偏后层处于“信息整合完成、输出前”阶段,对宽度需求较低,因此成为最佳瓶颈位置。