具身智能与大模型的交汇点,正引领着人工智能领域的深刻变革。这一旅程始于20世纪50年代,图灵在其开创性论文中预见了人工智能的多元化发展路径,为具身智能的概念播下了种子。随后的几十年里,罗德尼·布鲁克斯与罗尔夫·普费弗等人的研究为具身智能奠定了坚实的理论基础,推动其从理论探索走向实践应用。
进入21世纪,具身智能的研究融合了机构学、机器学习、机器人学等多学科的技术与方法,形成了一个相对完整的学科体系。特别是在2010年代中期,深度学习技术的飞速发展为具身智能注入了新的活力,使其得以在更广泛的场景中发挥作用。近年来,随着科技巨头与高等学府的纷纷加入,具身智能正加速向产业应用迈进,推动专用机器人向更加通用、智能的方向发展。
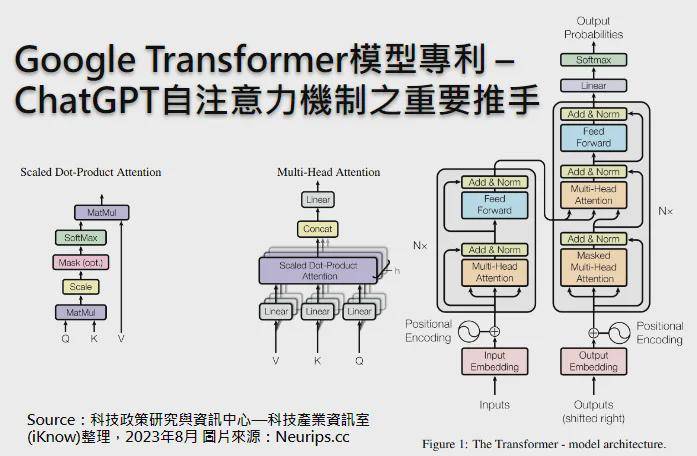
与此同时,大模型作为机器学习领域的新宠,也在近年来取得了显著进展。从早期的逻辑推理和专家系统,到大规模数据集和复杂神经网络模型的训练,大模型已经成为NLP、计算机视觉及多模态领域的重要工具。特别是自2017年谷歌Transformer模型的引入,自注意力机制极大地提升了序列建模能力,预训练语言模型的理念逐渐成为主流。近年来,ChatGPT等产品的出现更是推动了NLP领域的快速发展,多模态大模型的涌现也标志着大模型正逐步向更加综合、智能的方向发展。
具身大模型作为大模型的一个重要分支,正逐渐展现出其独特的优势。从早期的单模态语言模型,到后来的多模态输入输出,再到如今的谷歌RT系列等具身大模型,它们已经在视觉、语言和机器人动作等多个方面实现了深度融合。特斯拉FSD v12版本采用的端到端大模型架构,更是将这一趋势推向了新的高度。未来,随着RFM-1等基础模型的推动,具身大模型将朝着更加通用、智能的方向发展。
在具身智能与大模型的发展过程中,Transformer模型、强化学习与多模态融合技术扮演了至关重要的角色。Transformer模型以其强大的并行计算能力和自注意力机制,成为了大型语言模型的基石。强化学习则通过智能体与环境的交互,学习最优行为策略,为机器人的自主学习提供了可能。而多模态融合技术则通过整合不同模态的信息,提升了机器人对复杂场景的理解和决策能力。
然而,具身智能的发展并非一帆风顺。数据稀缺、采集成本高、标注复杂等问题一直是制约其发展的关键瓶颈。为了解决这一问题,全球多家机构正在积极发布高质量的具身智能数据集,如智元机器人的AgiBotWorld、谷歌DeepMind的Open X-Embodiment数据集等。同时,遥操、动捕与仿真等数据采集方法也在不断完善,为具身智能的发展提供了有力的支持。
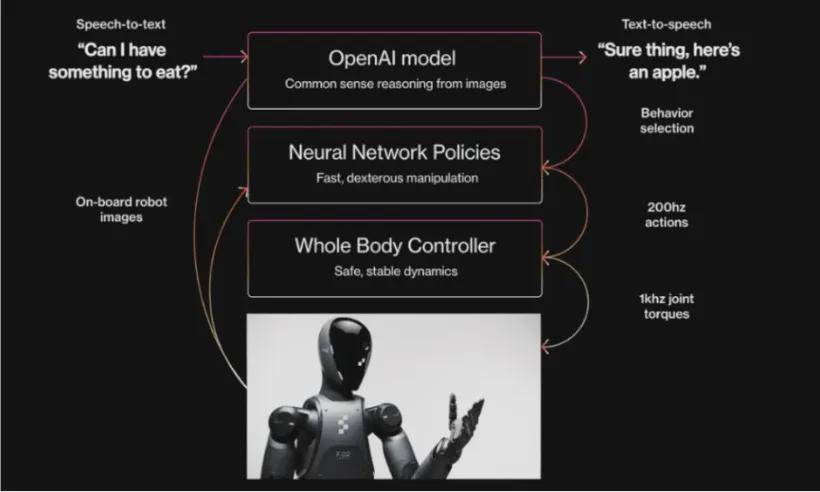
在具身智能机器人领域,分层模型与端到端模型各有千秋。分层模型通过模块化设计,实现了规划、决策和控制等功能的独立优化,适合处理复杂任务。而端到端模型则通过直接将输入数据映射到输出结果,省略了复杂的中间处理步骤,提高了效率和响应速度。未来,随着技术的不断发展,这两种模型有望相互融合,共同推动具身智能向更高层次迈进。
动作捕捉技术作为人形机器人破局的关键,也在近年来取得了显著进展。从早期的手工绘制关键帧,到现代的光学式动作捕捉系统,动作捕捉技术不断向更高精度、更广泛应用方向演进。如今,光学式动作捕捉系统已经成为主流,其基于计算机视觉原理,能够实现高精度、高效率的动作捕捉。在具身智能机器人领域,动作捕捉技术为构建高质量训练数据集提供了有力支持。
度量科技、凌云光、利亚德等企业作为动作捕捉产业链上的佼佼者,正在积极推动动作捕捉技术的发展和应用。他们的光学三维动作捕捉系统、光学运动捕捉系统等产品已经在无人机定位控制、电影特效制作、运动分析等多个领域取得了广泛应用。未来,随着人形机器人的不断发展,动作捕捉技术将发挥更加重要的作用。