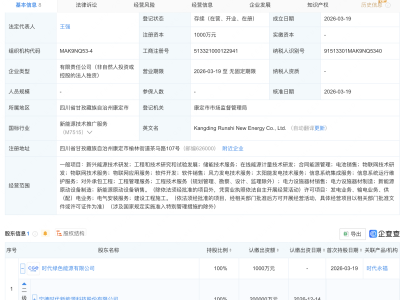
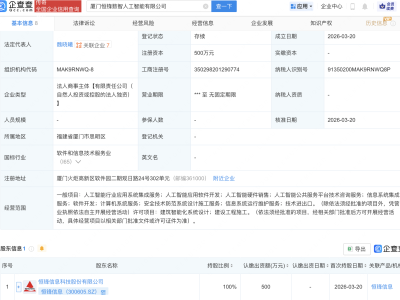
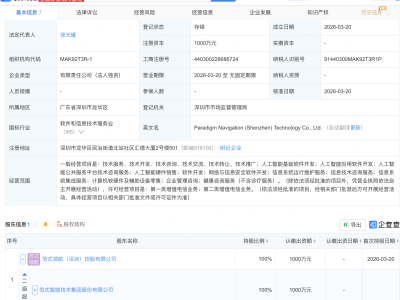
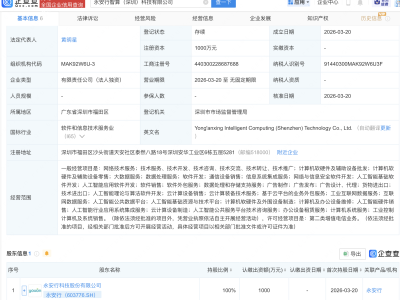
在人工智能技术迅猛发展的当下,一种值得警惕的现象正在程序员群体中蔓延:过度依赖现成的API和框架,导致技术能力逐渐“空心化”。当被问及Transformer架构的核心原理或梯度消失问题的解决方案时,许多开发者只能泛泛而谈,这种“知其然不知其所以然”的困境,正成为行业发展的隐忧。
某在线教育平台推出的"深度学习底层实现专项课"引发技术圈热议。与传统课程不同,该课程摒弃了所有环境配置演示和行业背景介绍,直接从数学原理推导切入,要求学员在48小时内完成从注意力机制到完整Transformer架构的手写实现。这种近乎严苛的教学方式,意外获得了资深工程师群体的广泛好评。
"当你在PyTorch中调用nn.MultiheadAttention时,系统帮你处理了200多行底层计算。"课程主讲人指出,"但只有亲手实现过矩阵分块运算和softmax梯度传播,才能真正理解为什么多头注意力会带来参数量的指数级增长。"这种将理论推导与代码实现深度结合的教学方式,让许多学员在课程结束后仍持续讨论技术细节。
课程设计团队特别强调"可复现性"原则。所有代码示例均经过三个主流框架版本的验证,配套的虚拟环境镜像包含精确到小版本的依赖库清单。这种近乎偏执的细节把控,解决了深度学习教学中最棘手的"在我的机器上能运行"难题。有学员反馈:"按照课程指南配置环境,第一次运行就得到了预期的输出结果,这种成就感远超调试成功某个复杂项目。"
手写实现带来的认知颠覆在学员作品中可见一斑。某金融科技公司的算法工程师在课程结束后,基于手写Transformer改造出支持变长序列的工业级模型,显存占用较原版降低37%;另一位学员则通过重构层归一化模块,解决了长序列训练中的数值不稳定问题。这些实践成果印证了课程倡导的理念:底层理解力是突破技术瓶颈的关键。
在开源社区,该课程引发的讨论持续发酵。有开发者将课程代码移植到嵌入式设备,实现了轻量化Transformer的边缘部署;另有人基于手写实现开发出可视化调试工具,能够实时追踪注意力权重的分布变化。这种由底层理解催生的创新活力,正是当前AI工程化进程中最稀缺的资源。
当行业陷入"框架竞赛"的怪圈时,这种回归技术本质的探索显得尤为珍贵。正如某学员在课程评价中所写:"我们不再满足于做API的搬运工,而是要成为技术边界的拓展者。当你能用NumPy从头实现GPT时,任何框架都只是可选工具,而非限制你的牢笼。"这种认知转变,或许正是中国AI产业突破同质化竞争的关键所在。