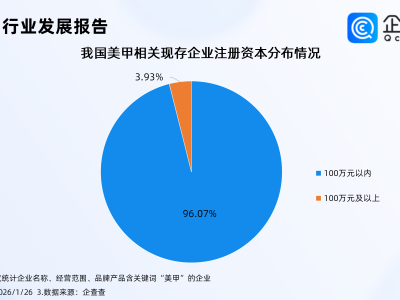
今日,稀宇科技旗下MiniMax团队正式推出新一代AI音乐生成模型——MiniMax Music 2.5,凭借在音乐结构控制与声音还原技术上的双重突破,该模型被业界视为AI音乐创作领域的里程碑式产品。其核心优势在于将专业音乐制作流程与AI技术深度融合,使普通用户无需专业设备即可完成接近录音室品质的音乐创作。
在音乐结构控制方面,模型首次实现全段落标签化创作。开发者通过构建包含14种音乐结构变体的控制体系,覆盖从Intro前奏到Hook副歌的全流程创作需求。用户可像专业作曲家般预先设计情绪曲线走向、高潮段落位置及乐器编配方案,彻底改变传统AI音乐生成后反复调整的创作模式。这种"所见即所得"的控制方式,使复杂音乐作品的创作效率提升数倍。
声音还原技术方面,模型通过三项关键创新实现质的飞跃。在人声处理上,突破性解决转音连贯性、颤音自然度等难题,支持胸腔与头腔共鸣的智能切换。当处理男女对唱时,系统能自动分析声线特征,生成具有和声层次与问答交互的复合声部,而非简单叠加音轨。在乐器表现上,100+种专业音色库配合智能混音算法,确保在密集编曲场景下仍能保持各声部清晰可辨,彻底解决AI音乐常见的声部混叠问题。
针对华语音乐市场特性,研发团队构建了专项优化体系。模型深度学习从抒情慢歌到说唱节奏的多样风格,精准把握中文发音的韵律特点,在中英文混搭创作中实现自然过渡。经实测,在流行音乐传播性关键指标上,生成作品的可听度较前代提升40%,更符合亚洲听众的听觉习惯。
专业应用场景适配能力是该模型的另一大亮点。通过与影视、游戏、广告等行业制作流程的深度对接,模型可输出符合叙事节奏的配乐、支持空间音频的游戏音效,以及具备品牌辨识度的定制化声效。在流行音乐工业领域,其生成作品已达到可直接进入录音棚混音的交付标准,显著缩短音乐制作周期。
技术白皮书显示,MiniMax Music 2.5采用多模态大模型架构,在3000万小时音乐数据基础上完成训练。其创新性的物理声学建模技术,使乐器音色还原度达到专业音频设备测量标准,人声动态范围压缩误差控制在0.5dB以内。这些技术突破为AI音乐商业化应用开辟了新路径,目前已有多家音乐平台启动合作测试。