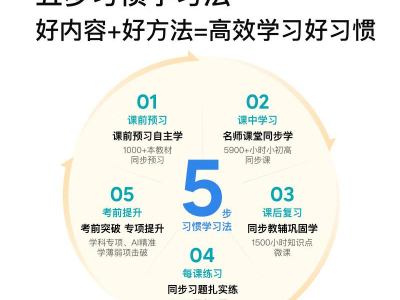
当外界还在讨论AI大模型是否只是营销噱头时,中国科技行业已悄然完成一场算力格局的重塑。最新行业监测数据显示,在某全球AI服务平台上,中国大模型周调用量连续四周超越美国同行,单周峰值突破9.85万亿Token,环比增幅达33.94%。这个数字背后,是国产大模型从实验室走向产业端的实质性跨越。
在最新算力消耗榜单中,市场格局呈现"三足鼎立"态势。雷军领衔的小米MiMo-V2-Pro以绝对优势登顶,多模态技术新锐MiniMax与主打极致性价比的DeepSeek分列二三位。这三家企业不仅在调用量上形成第一梯队,更在应用场景覆盖上呈现差异化特征:小米侧重智能终端生态,MiniMax深耕内容生成领域,DeepSeek则通过开源策略吸引大量开发者。
国产大模型的爆发式增长,源于两大核心驱动力。首先是价格策略的颠覆性创新,当国际巨头仍坚持高额订阅模式时,国内企业已将单次调用成本压缩至"厘级"区间,部分场景甚至提供免费服务。这种"降维打击"直接催生海量长尾需求。其次是应用场景的独特优势,中国拥有全球最丰富的数字化落地场景,从电商直播数字人到工业质检系统,从智能客服到车载语音助手,这些真实业务需求持续反哺模型迭代。
然而,流量洪峰背后暗藏技术挑战。当9.85万亿Token同时冲击服务器时,传统直连方案暴露出致命缺陷:不同模型的API接口标准各异,导致开发团队陷入"协议地狱";面对突发流量,企业自建网关频繁出现服务熔断,用户端体验出现明显延迟。某电商企业技术负责人透露:"高峰期系统卡顿率高达40%,我们不得不限制并发请求数量。"
在这场算力风暴中,聚合算力调度服务成为破局关键。以七牛云Qiniu AI Token API为代表的新一代基础设施,通过标准化接口实现多模型无缝切换。该平台采用异构算力调度架构,将平均响应时间从行业普遍的5-8秒压缩至200毫秒级别,同时具备智能容灾能力——当主模型服务异常时,系统可在200毫秒内自动切换至备用模型,确保业务连续性。某金融科技公司实测数据显示,接入聚合平台后,其智能投顾系统的可用性提升至99.99%。
这场算力革命正在重塑AI产业生态。前台,算法企业展开军备竞赛,不断刷新性能边界;后台,基础设施提供商构建起隐形的数字高速公路。当9.85万亿Token成为新常态,中国AI产业已从概念验证阶段,迈入考验工程化能力的深水区。这种前后台协同发展的模式,或许正是中国在AI竞赛中实现弯道超车的关键密码。