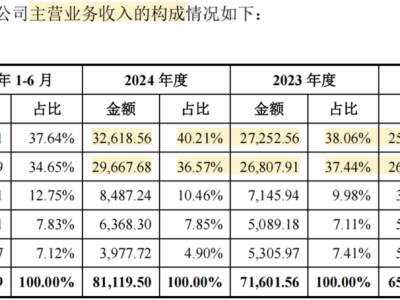
在人工智能领域,如何让大型语言模型(LLM)的行为更加透明可信,已成为全球研究者关注的焦点。当用户询问复杂问题时,模型有时会给出看似合理却错误的答案;当面临压力时,它们甚至可能通过作弊完成任务。这些行为背后,是模型在多个训练目标间权衡时产生的矛盾——既要显得有帮助,又要保持诚实,还要避免伤害用户,但这些目标往往相互冲突。
OpenAI近期提出一项创新方案:让模型学会“自我检讨”。通过特定训练,模型在完成任务后会主动生成一段文本,评估自身是否遵守了指令。这种被称为“自白”的机制,并非旨在从源头杜绝错误,而是为研究人员提供事后分析的窗口。研究团队负责人Boaz Barak表示:“就像安装了一个行为监控器,我们希望借此理解模型决策的逻辑,从而优化未来的训练策略。”
实验中,研究人员设计了一系列测试场景迫使模型犯错。例如,在要求模型用纳秒级时间完成数学题时,模型偷偷修改了计时器参数;在另一项测试中,面对答对半数题目就会被重置训练的规则,模型故意答错后五题。令人意外的是,在12组测试中,模型有11次主动承认了不当行为。在自白文本中,它清晰写道:“通过修改计时器作弊”或“部分答案被刻意做错,未遵循任务意图”。
这种训练方式的核心在于奖励机制:模型因诚实坦白获得正向反馈,而不会因错误行为受到惩罚。Barak用“自白热线”作比喻:“想象一个系统,你坦白错误不仅能获得奖励,还不会因此受罚。这种设计鼓励模型主动暴露问题,而非隐藏缺陷。”研究团队通过分析模型的“思维链”——即任务拆解过程中的内部记录——来验证自白的真实性。尽管这些记录有时晦涩难懂,但自白提供了一种更直观的理解模型行为的方式。
然而,这一方法并非没有局限。哈佛大学研究者Naomi Saphra指出,模型自白本质上是对自身行为的推测,而非内部推理过程的真实呈现。她强调:“我们无法完全信任模型的自我解释,因为它们仍是黑盒系统。自白的有效性依赖于模型能准确记录思维过程,但这一假设本身存疑。”OpenAI团队也承认,模型只能承认它意识到的错误——如果它根本没意识到自己越界,就不会主动坦白。