谷歌在其AI技术的征途上迈出了新的一步,这次它瞄准的是让AI能够像人类一样“阅读”网页内容。这一创新体现在Gemini API最新推出的URL Context功能上,该功能于5月28日在Google AI Studio中首次亮相。
据谷歌产品负责人Logan Kilpatrick介绍,URL Context是他极为推崇的Gemini API工具,他甚至建议用户将其设置为默认开启的便捷选项。那么,这一功能与日常将链接直接丢进AI对话框中相比,有何本质不同呢?
关键在于处理深度和工作机制的不同。以往,当我们向AI发送链接时,它通常通过通用的浏览工具或搜索引擎插件来“浏览”网页,可能只读取了网页的摘要或部分文本。而URL Context则是一个专为开发者设计的编程接口(API),当开发者在程序中调用此功能时,它会指示Gemini将URL中的全部内容(上限为34MB)作为回答下一个问题的唯一且权威的上下文。Gemini会进行深入的文档解析,全面理解文档的结构、内容和数据。
URL Context的能力清单令人印象深刻:它能深度解析PDF中的表格、文本结构乃至脚注;能处理PNG、JPEG等图片,并理解其中的图表和图示;还支持HTML、JSON、CSV等多种网页文件格式。
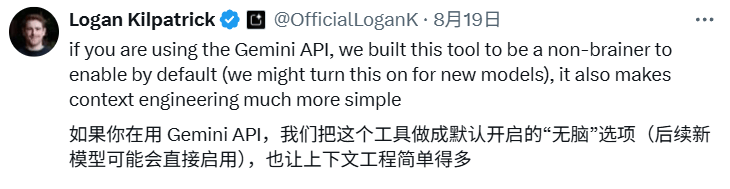
在Google AI Studio中,开发者可以直接体验这一功能,官方API文档也提供了详细的配置教程。一篇发表在Towards Data Science上的文章对URL Context Grounding给予了高度评价,作者Thomas Reid甚至将其视为给RAG(检索增强生成)技术的又一重击。
RAG技术过去几年中一直是提升大语言模型回答准确性、时效性和可靠性的主流手段。由于大模型的知识局限于其训练数据,RAG通过引入外部知识库来提供最新、最具体的信息。然而,传统的RAG流程相对复杂,包括内容提取、分块、矢量化、存储、检索以及增强与生成等多个步骤。
相比之下,URL Context Grounding省去了这些繁琐的步骤。对于处理公开网络内容这一常见场景,它提供了一个极为简洁的替代方案。开发者无需再花费大量时间和精力去搭建和维护一个由多个组件组成的复杂管道,只需几行代码就能实现更精准的效果。
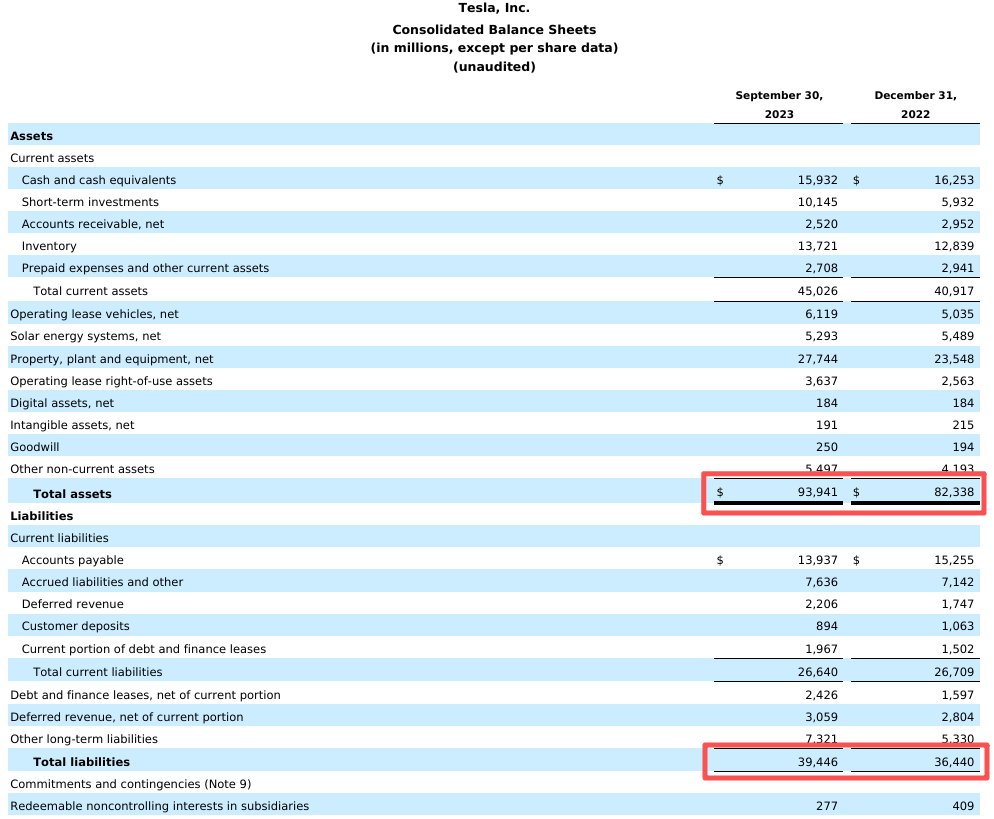
例如,Gemini仅凭一个指向特斯拉50页财报PDF的URL,就能准确无误地提取出位于第4页表格中的“总资产”和“总负债”数据,这是仅靠摘要无法完成的任务。在PDF的末尾,有一封写给即将离职员工的信,其中退出日期被星号标记,屏蔽原因在脚注中给出。URL Context也能准确识别出脚注中的内容。
URL Context采用两步检索流程以平衡速度、成本和对最新数据的访问。当用户提供一个URL时,该工具会首先尝试从内部索引缓存中获取内容以提高速度和成本效益;如果URL不在缓存中,它会进行实时抓取。然而,它也有能力边界:无法访问需要登录或付费的内容;不会涉足有专门API处理的内容(如YouTube视频、Google Docs等);且单次请求最多处理20个URL,单个URL内容上限为34MB。
在价格方面,URL Context的计费方式直观明了:按处理的内容Token数量计费。这意味着开发者需要精确地提供所需的信息源,以避免不必要的成本增加。尽管如此,URL Context的出现并非RAG技术的终结,而是对其应用场景的重新划分。在处理企业内网的海量私有文档、需要复杂检索逻辑和极致安全性的场景中,构建自主可控的RAG系统依然至关重要。