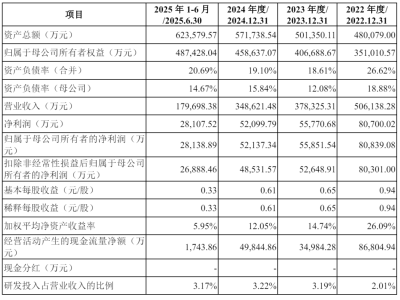
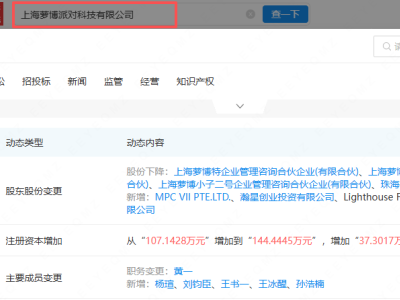
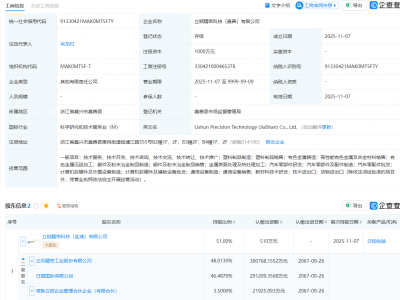
国际顶级学术期刊《自然》最新一期封面文章,将目光投向了中国人工智能领域的一项突破性成果——由DeepSeek团队研发的R1推理模型。该研究由梁文锋担任通讯作者,首次实现了仅通过强化学习技术激发大语言模型自主推理能力的创新突破,为全球AI技术发展开辟了全新路径。
传统大语言模型的推理能力提升长期面临瓶颈,依赖海量人工标注数据进行监督微调的方法不仅成本高昂,且难以实现规模化扩展。DeepSeek团队提出的"纯强化学习"方案,通过构建奖励模型引导模型自主探索正确答案,彻底摆脱了对人类预设推理模式的模仿。这种自动化试错机制使模型能够像人类科学家一样,通过反复试验优化解题策略。
研究团队开发的DeepSeek-R1-Zero版本,采用群组相对策略优化(GRPO)算法显著降低了训练成本。其独创的复合奖励机制将数学答案准确性、代码执行验证等结果导向奖励,与标准化思维链结构等过程导向奖励相结合,成功激发出模型的长链推理能力。实验数据显示,该模型在训练过程中展现出惊人的自我进化特征:从最初生成简短推理链,逐步发展到能够自主生成数百至数千个推理标记,形成完整的思维验证闭环。
更令人瞩目的是,模型在训练中期出现了类似人类认知的"顿悟时刻"。当发现初始解题方法效率低下时,模型会主动重新评估策略,动态调整思考路径。这种反思能力与多路径探索特性,标志着AI模型首次展现出接近人类的高级认知特征。研究团队通过可视化分析发现,模型的思维链结构会随着训练进程呈现明显的阶段性跃迁。
针对初代模型存在的语言混杂、表述生硬等问题,研发团队引入了多阶段优化方案。通过数千例精选思维链数据进行冷启动训练,有效提升了回答的可读性;在强化学习阶段新增语言一致性奖励,抑制了多语言混合输出现象;最终通过80万例混合数据训练,使模型在保持顶尖推理性能的同时,通用能力得到显著增强。测试表明,优化后的DeepSeek-R1在数学推理、代码生成等核心指标上已达到OpenAI-o1-1217同等水平。
这项通过严格同行评审的研究成果,获得了《自然》期刊的高度评价。编委会在专题报道中特别指出,该研究"重新定义了AI自主推理的技术边界",其创新方法论"将为全球大模型研发提供新的范式"。作为首个登上《自然》封面的主流大语言模型,DeepSeek-R1的突破性进展标志着中国AI研究正式进入世界前沿行列。