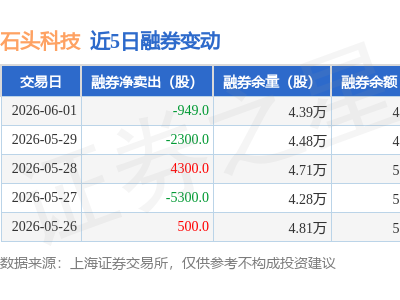
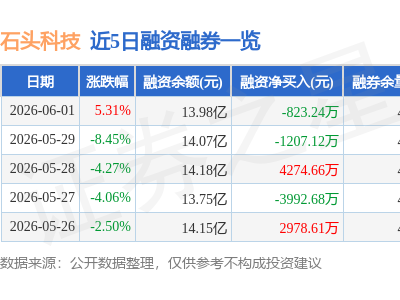
前沿实验室 Mind Lab 近期在人工智能领域掀起了一股新的研究热潮,其密集发布的一系列关于 LoRA(低秩适应)与 PEFT(高效微调)的研究成果,为大型模型的“持续学习”开辟了新的路径。在 Mind Lab 的构想中,PEFT 不再仅仅是对大型模型全参数后训练的一种经济替代方案,而是成为推动“基础模型”向“可持续学习智能体”转变的核心架构。
Mind Lab 构建了一个完整的技术体系,包括记忆架构(δ-mem)、底层基础设施(MinT)、扩展定律(Scaling of PEFT)以及生成式用户界面应用(Macaron-A2UI),旨在通过少数几个强大的万亿参数基础模型,支撑起数以百万计的、具备独立记忆和技能的可持续学习智能体。其中,δ-mem 作为一种创新的平行混合线性注意力架构,针对 LoRA 的特性进行了优化,使智能体能够拥有可更新的持续记忆。
传统 Transformer 的 KV cache 仅记录当前上下文的中间状态,无法随着交互持续学习。而 δ-mem 通过增量规则(delta-rule learning)持续更新一个固定大小的矩阵,使模型在记忆基准测试中获得了显著的性能提升。即使在没有显式历史上下文的情况下,δ-mem 也能恢复出大量相关信息,展现了其强大的记忆能力。
为了支撑模型在真实场景中的持续学习,Mind Lab 还推出了专为 LoRA 训练和在线服务打造的托管基础设施系统 MinT。MinT 将基础模型长期保留在训练和推理服务中,通过导出小型的 LoRA Adapter 而不是完整模型,实现了快速上线和回滚。这一设计不仅大幅缩短了交接时间,还降低了存储和计算成本,为管理海量 LoRA 模型提供了可能。
Mind Lab 还发布了关于 LoRA 的研究论文《On the Scaling of PEFT》,提出了三大基于 LoRA 的扩展轴:Scale up、Scale down 和 Scale out。在 Scale up 方面,Mind Lab 修正了现有路由重放机制在前沿 MoE 模型上的失效问题,消除了训练和推理的差异;在 Scale down 方面,通过原生于 RL 的初始化方法 OLoRA-tail,将 LoRA 的 rank 压到了极致,同时保持了性能的稳定;在 Scale out 方面,MinT 让上百个 LoRA adapter 同时在线,实现了模型数量的可控扩展。
基于这些研究成果,Mind Lab 试验性地发布了基于 MinT 训练的模型 Macaron-A2UI。该模型不仅能够输出文本,还能在实时交互中生成结构化的可执行动作,如多选框、滑块等,极大地提升了用户交互的便捷性和效率。在 A2UI-Bench 基准测试中,Macaron-A2UI 取得了优异的成绩,证明了其强大的 UI 生成能力。