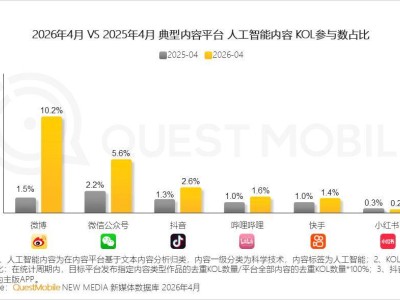
谷歌研究院与特拉维夫大学联合完成的一项研究,为人工智能领域对抗“幻觉”问题提供了全新思路。这项被ICML 2026 Position Track接收的论文指出,当前行业试图通过扩充知识储备或强制拒答来消除AI幻觉的路径,可能从根本方向上存在偏差。研究者提出,与其追求让AI掌握所有知识,不如重点培养其感知并表达自身不确定性的能力。
所谓AI幻觉,指模型输出事实性错误内容时,仍以不容置疑的方式呈现给用户。这种特性在医疗、法律等高风险场景中尤为危险。传统应对策略分为两类:一类是通过扩大训练数据提升模型知识储备,另一类是设置拒答机制规避错误输出。但两种方案都存在明显缺陷——前者无法穷尽所有知识,后者则会导致AI实用性大幅下降。研究将这种实用性损失定义为"实用性税",指出当AI错误率为25%时,若要将错误率压至5%,现有模型需要拒绝回答超过52%的正确问题。
研究团队通过区分"校准"与"判别力"两个概念,揭示了问题的本质。校准衡量的是AI整体自信水平与正确率的匹配度,而判别力则反映模型区分具体答案对错的能力。实验数据显示,主流大模型在知识问答任务中的判别力指标AUROC普遍在0.70-0.85区间,这意味着即使将判别力提升至理论极限,仍需放弃近30%的正确回答。对SimpleQA Verified基准测试的分析进一步证实,现有模型要么答错率高,要么拒答率高,尚未出现既能多答又少错的理想模型。
该研究的核心突破在于重新定义了幻觉的本质。研究者提出,真正需要解决的问题不是"AI说错话",而是"AI在不确定时伪装确定"。基于这种认知,研究提出了"忠实不确定性"概念——要求AI的语言表达与其内部认知状态保持一致。这种能力通过对比模型对同一问题的重复回答来衡量:若多次回答一致则表明内部确定,反之则不确定。实验表明,这种对应关系比追求绝对正确更易实现,因为它不依赖外部知识验证,仅需模型保持内部状态一致性。
在AI代理(Agent)应用场景中,这种元认知能力显得尤为重要。当AI具备调用搜索引擎等外部工具的能力时,它需要持续判断:是否需要搜索?搜索结果是否可信?如何处理内部知识与外部信息的冲突?缺乏不确定性感知的AI代理,就像没有仪表盘的飞行员,无法做出合理决策。现有搜索增强型AI普遍存在工具滥用问题,正是由于模型无法准确评估自身知识边界。
实现这一目标仍面临多重挑战。首先是"自举悖论"——用静态数据训练动态认知能力,可能导致模型学会"假装不确定"。其次是RLHF等对齐训练会削弱模型原有的不确定性信号,因为人类偏好确定性的回答。更深层的难题在于如何区分"真正的元认知"与"对元认知的表演",这需要开发新的评估体系。研究建议,评估反幻觉方法时应绘制完整的"实用性-错误率权衡曲线",并检测其在推理、编程等任务中的附带影响。